
Elasticsearch 101: มันง่ายกว่าที่คิด มาลองเล่นกัน!
Elasticsearch คืออะไร
Elasticsearch คือ ที่เก็บข้อมูลที่พัฒนาต่อยอดมาจาก Apache Lucene มีจุดเด่นในเรื่องความสามารถของการค้นหา และสรุปข้อมูลขนาดใหญ่ได้อย่างรวดเร็ว
เกริ่น: ทำไม ThothZocial ถึงเลือกใช้ Elasticsearch?
1. ทำงานได้เร็ว
Elasticsearch มีการทำ index ข้อมูลไว้ในทุกๆ field ข้อมูล ทำให้ค้นหาและสรุปข้อมูลข้อมูลขนาดใหญ่ได้อย่างรวดเร็วใกล้เคียงกับการเข้าถึงข้อมูลแบบ Near Real-time
2. เก็บข้อมูลแบบในรูปแบบ JSON Document
Elasticsearch เลือกใช้การเก็บข้อมูลในรูปแบบ JSON (JavaScript Object Notation) ซึ่งเป็นรูปแบบมาตรฐานข้อมูลที่ใช้งานได้ง่าย รับส่งข้อมูลได้หลากหลายแพลตฟอร์ม
3. ใช้งานง่ายผ่าน HTTP API
4. รวบรวม และสรุปข้อมูลเพื่อนำมาแสดงผลได้ง่าย
อีกหนึ่งจุดเด่นของ Elasitcsearch นั้นคือ การสรุปผลข้อมูลเชิงสถิติ เพื่อนำมาสร้างเป็นตาราง กราฟต่างๆ หรือ แสดงเป็นแผนที่ได้ง่าย
5. ทำงานแบบกระจาย และรองรับการขยายได้ง่าย
ตัวอย่างวิธีการใช้งานการใช้งาน Elasticsearch
การใช้งาน Elasticsearch นั้นเริ่มต้นได้ไม่ยาก เริ่มจากลองมา start elasticsearch node ด้วย docker
คำสั่งสำหรับ start Elasticsearch node ด้วย Docker
shell
docker run --detach --name elasticsearch \
--publish 9200:9200 \
--env "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch-oss:6.1.2
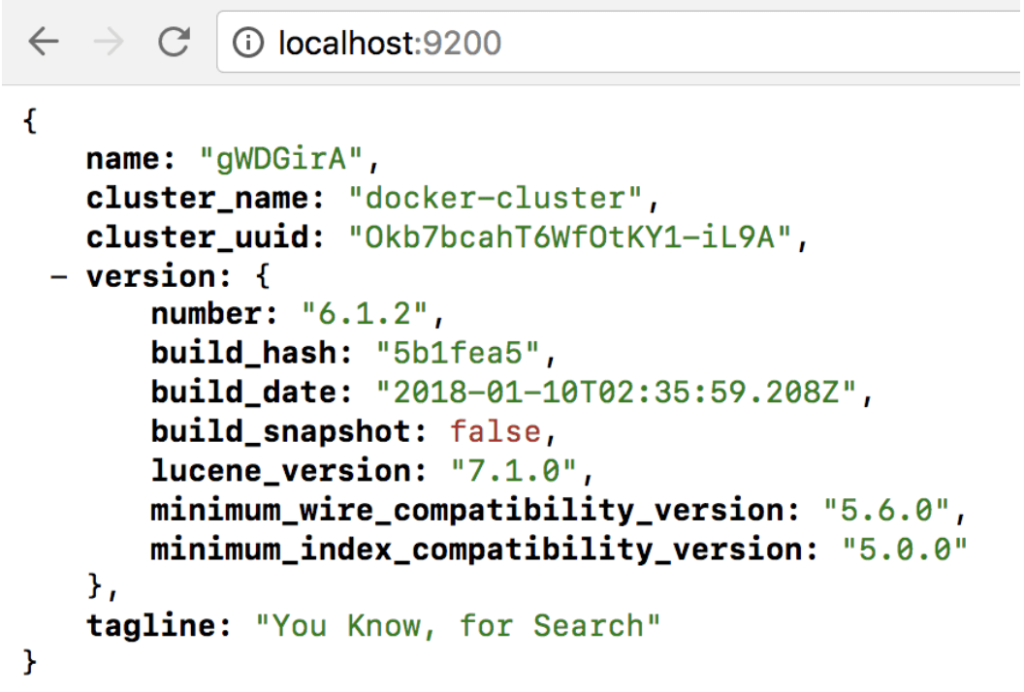
และลองเข้า browser เปิดไปที่ http://localhost:9200 จะเห็นข้อมูลของ Elasticsearch ที่ใช้งานอยู่
แต่ละ document ใน Elasticsearch จะถูกเก็บลงใน index และ type เปรียบได้กับ database และ table ของ SQL
ลองมาสร้าง index, type และ mapping โดยจะใช้ index ที่ชื่อ messages และมี type ที่ชื่อ message
ตัวอย่าง mapping
json
{
"mappings": {
"message": {
"properties": {
"message": {
"type": "text"
},
"username": {
"type": "keyword"
}
}
}
}
}
สร้าง mapping ด้วยคำสั่ง curl
shell
curl -H "Content-Type: application/json" \
-X PUT "http://localhost:9200/messages" \
-d \ '{"mappings":{"message":{"properties":{"message":{"type":"text"},"username":{"type":"keyword"}}}}}'
และลองเพิ่มข้อมูลลงใน index
shell
curl -H "Content-Type: application/json" \
-X PUT "http://localhost:9200/messages/message/1" \
-d '{"message":"Hello Pattanapong.","username":"lattapon"}'
curl -H “Content-Type: application/json” \
-X PUT “http://localhost:9200/messages/message/2” \
-d ‘{“message”:”How are you today?”,”username”:”lattapon”}’
curl -H “Content-Type: application/json” \
-X PUT “http://localhost:9200/messages/message/3” \
-d ‘{“message”:”I’m fine.”,”username”:”pattanapong”}’
การ query สามารถทำได้โดยการส่ง HTTP Get Request ไปที่ index, type และ id ที่ต้องการ
shell
curl -X GET "http://localhost:9200/messages/message/1"
ลองสรุปข้อมูล username ด้วยการ aggregation: ตัวอย่าง dsl query
json
{
"query": {
"match_all": {}
},
"aggs": {
"users": {
"terms": {
"field": "username",
"size": 10
}
}
},
"size": 0
}
Query ข้อมูลด้วยคำสั่ง curl
shell
curl -H "Content-Type: application/json" \
-X GET "http://localhost:9200/messages/message/_search" \
-d \ '{"query":{"match_all":{}},"aggs":{"users":{"terms":{"field":"username","size":10}}},"size":0}'
คำแนะนำในการใช้งาน Elasticsearch
เนื่องจากความง่ายในการใช้งานของ Elasticsearch หลายคนจึงเอามาใช้งานโดยไม่ได้คำนึงถีงเรื่องที่สำคัญหลายๆ เรื่องไป ได้แก่
1. วางแผนก่อนใช้งานจริง
ก่อนนำ Elasticsearch ไปใช้งานจริง ควรทดสอบการใช้งานใน use case ที่ต้องการใช้งานด้วย traffic ที่ใกล้เคียงกัน พร้อม optimize ให้มีประสิทธิภาพเพียงพอ และควรคำนวนอัตราการเติบโตของข้อมูลเพื่อเตรียมการขยายตัวในอนาคต
2. สร้าง mapping ก่อนการใช้งาน
Elasticsearch จะพยายามกำหนด mapping ให้กับข้อมูลอัตโนมัติ เช่น ถ้า field ของข้อมูลเป็นตัวอักษร Elasticsearch จะกำหนดให้ mapping ของ field นั้นเป็น text ซึ่งจะมีการวิเคราะห์ และตัดคำในเบื้องหลังเพื่อใช้ในการค้นหา แต่ถ้าข้อมูลของเรามี field จำนวนมาก หากปล่อยให้ Elasticsearch ตัดคำสำหรับทุก field ก็จะทำให้ประสิทธิภาพการทำงานของ Elasticsearch ต่ำลง เพราะฉะนั้น เราควรกำหนด mapping ให้เหมาะสมกับการใช้งาน
3. คำนึงถึงเรื่องความปลอดภัย
Elasticsearch ไม่มีฟิเจอร์ด้านความปลอดภัยติดตั้งมาให้ด้วย ทำให้ใครก็ตามที่เข้าถีง Elasticsearch สามารถเข้าถึงข้อมูลและเปลี่ยนแปลงข้อมูลของเราได้ เมื่อนำไปใช้งานจริง จึงควรใช้งานไฟล์วอลล์หรือระบบระบุตัวตนก่อนเพื่อความปลอดภัย
4. การตั้งค่าเมื่อใช้งานใน production
- เนื่องจาก Elasticsearch สร้างด้วยภาษา Java การใช้งานจึงต้องติดตั้ง JDK และควรใช้เวอร์ชันล่าสุดเสมอ
- กำหนด JAVA HEAP SIZE ของ Elasticsearch ไว้ที่ประมาณ 50% ของหน่วยความจำแต่ต้องไม่เกิน 32GB
- เนื่องจาก Elasticsearch มีการทำงานร่วมกับไฟล์จำนวนมากจึงควรใช้ SSD และตั้งค่า max opened files limitation บนระบบปฏิบัติการให้เพียงพอต่อการใช้งาน
- ไม่ควรใช้ค่าพื้นฐานโดยเฉพาะชื่อ cluster และชื่อ node และควรกำหนด data path ให้ชัดเจน
5. ใช้ Bulk API เมื่อต้องการเพิ่มหรือแก้ไขข้อมูลจำนวนมาก
การทำงานกับข้อมูลจำนวนมาก หากเราส่ง request ไปหา Elasticsearch ในทุกเอกสารที่ต้องการเพิ่มหรือแก้ไข จะทำให้ Elasticsearch ต้องรับ request เป็นจำนวนมากในระยะเวลาสั้นๆ ทำให้ Elasticsearch ทำงานหนักเกินความจำเป็น เพราะฉะนั้นเมื่อต้องแก้ไขหรือเพิ่มข้อมูลหลายๆ ข้อมูลพร้อมกันควรใช้ Bulk API เพื่อรวบรวมคำสั่งและส่ง request ไปเพียงครั้งเดียว
6. ใช้ Scroll API เมื่อต้อง query ข้อมูลจำนวนมาก
เมื่อต้องการข้อมูลจำนวนมากหรือทั้งหมดจาก Elasticsearch การ query ข้อมูลโดยกำหนด index และ offset จะทำให้ elasticsearch ต้องรับ search query จำนวนมากอาจส่งผลต่อประสิทธิภาพในการทำงาน ควรใช้งาน Scroll API แทนเพื่อ query ข้อมูลเพียงครั้งเดียวแล้วทยอยเอา result ออกมา
7. ตรวจสอบสถานะอยู่เสมอ
Elasticsearch มี API ให้สำหรับการตรวจสอบสถานะการทำงานของ cluster และ node ให้ใช้งานด้วย เช่น
- /_nodes สำหรับดูข้อมูลของแต่ละ node ใน cluster
- /_stats สำหรับดูสถิติในการใช้งาน
- /_cluster/health สำหรับดูข้อมูลและสถานะของ cluster
หวังว่าบทความนี้จะเป็นประโยขน์กับผู้เร่ิมใช้งาน Elasticsearch ทุกท่าน
บทความโดย: ทีมพัฒนา thothzocial.com
รูปประกอบบทความ: https://pixabay.com/en/rubber-rings-rubber-annular-2512269/



