

ด้วยลักษณะการใช้งาน platform ของ ThothZocial นั้น มีความจำเป็นที่ต้องเข้าไปค้นหาข้อมูลย้อนหลัง ซึ่งในส่วนของการประมวลผลนั้นต้องมีการค้นหาข้อมูลจำนวนมากกว่า 4,500 ล้านแถวของข้อมูล (1 ปี ย้อนหลังโดยประมาณ)
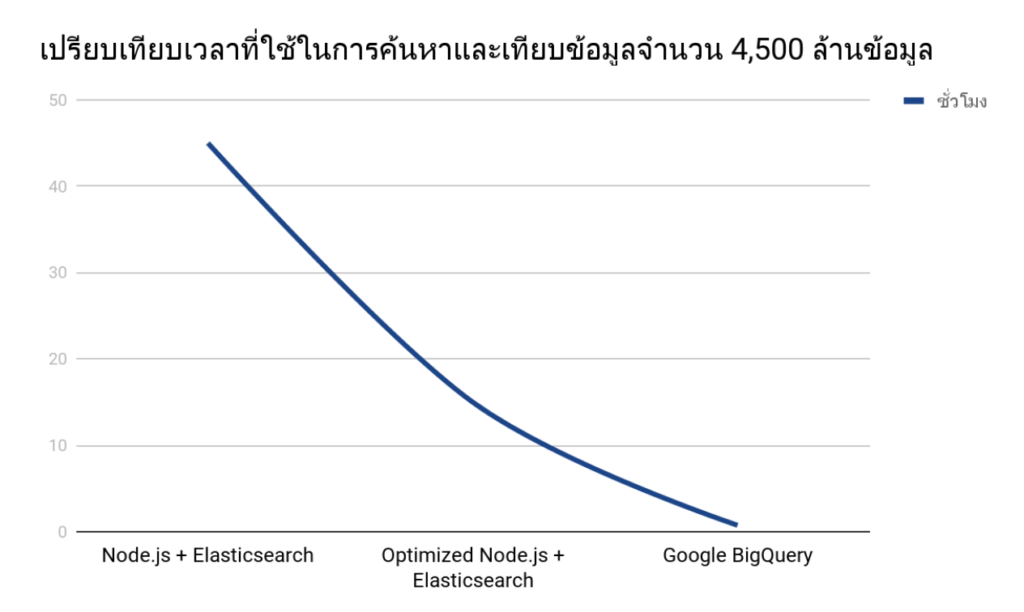
เมื่อก่อนนั้นเราต้องทำการเทียบข้อมูลเก่าเอง และด้วยข้อมูลมีปริมาณค่อนข้างมาก จึงทำให้เราใช้ MongoDB ค้นหาข้อความที่เราต้องการตรงๆ ไม่ไหว เราจึงลองใช้ Node.js และ Elasticsearch ในการค้นหาข้อมูล แต่ด้วยข้อจำกัดในการตัดคำภาษาไทย เราจึงต้องอ่านข้อมูลทีละแถวและมาทำการค้นหา ซึ่งทำให้ประมวลผลได้ช้ามาก (ในสมัยก่อนกรณีย้อนหลังข้อมูล 1 ปีก็ต้องใช้จำนวน loops มากถึง 4,500,000,000 คูณด้วยจำนวนคำที่เราต้องการโดยประมาณ) ระบบใช้เวลาในการประมวลผลมากถึง 48 ชั่วโมงกว่าจะทำงานเสร็จ
ภายหลังเราได้มีการปรับประสิทธิภาพในเรื่องนี้อีกครั้งหนึ่ง แต่ก็ยังต้องใช้เวลาในการค้นหาและเทียบข้อมูล นานถึงประมาณ 15 ชั่วโมง แต่ก็ยังช้าไปอยู่ดี สุดท้ายเราก็ได้ลองค้นหาวิธีการที่จะทำให้มันเร็วขึ้นกว่าเดิมและทดลองเครื่องมือหลายอย่างจนสุดท้ายมาจบที่ Google BigQuery ซึ่งเราคิดว่าน่าจะเป็น solution ที่เหมาะสมกับการใช้งานของเราที่สุด
— ทำไมไม่ลองใช้พวก Apache Spark, Elasticsearch หรือ ตั้งเซิฟเวอร์ไปเองเลยล่ะ
เรามองว่าการซ่อมบำรุงดูแลรักษาและขยายระบบเองนั้น น่าจะสิ้นเปลืองเวลาและค่าใช้จ่ายมากกว่าการใช้ตัวบริการ BigQuery
ถึงแม้ว่า tools เหล่านั้นจะ customize ได้มากกว่า แต่ด้วย use cases แล้วเราไม่ได้จำเป็นที่จะต้องใช้ความสามารถเหล่านั้น ตัว BigQuery เองก็ตอบโจทย์การใช้งานของเรา อีกทั้ง learning curve ค่อนข้างต่ำกว่าทำให้เราตัดสินใจเลือกวิธีนี้
— แล้วเราเอา BigQuery มาทำอะไรใน ThothZocial
เราใช้ BigQuery เป็นกรองข้อมูลตามที่เราสนใจในเบื้องต้น ก่อนที่จะเอา Reference ID ของ data ที่ได้ไปประมวลผลในส่วนอื่นๆ ต่อไปตามที่แต่ละ platform หรือลูกค้าสนใจ นอกจากนี้ยังใช้เป็นตัวหาข้อมูลที่เกี่ยวข้องกับข้อความต่างๆ แบบคร่าวๆ ได้อย่างรวดเร็ว เพื่อให้ทีม analyst สามารถหาข้อมูลโดยคร่าวๆ ได้อีกด้วย
ตัวอย่างการใช้งาน
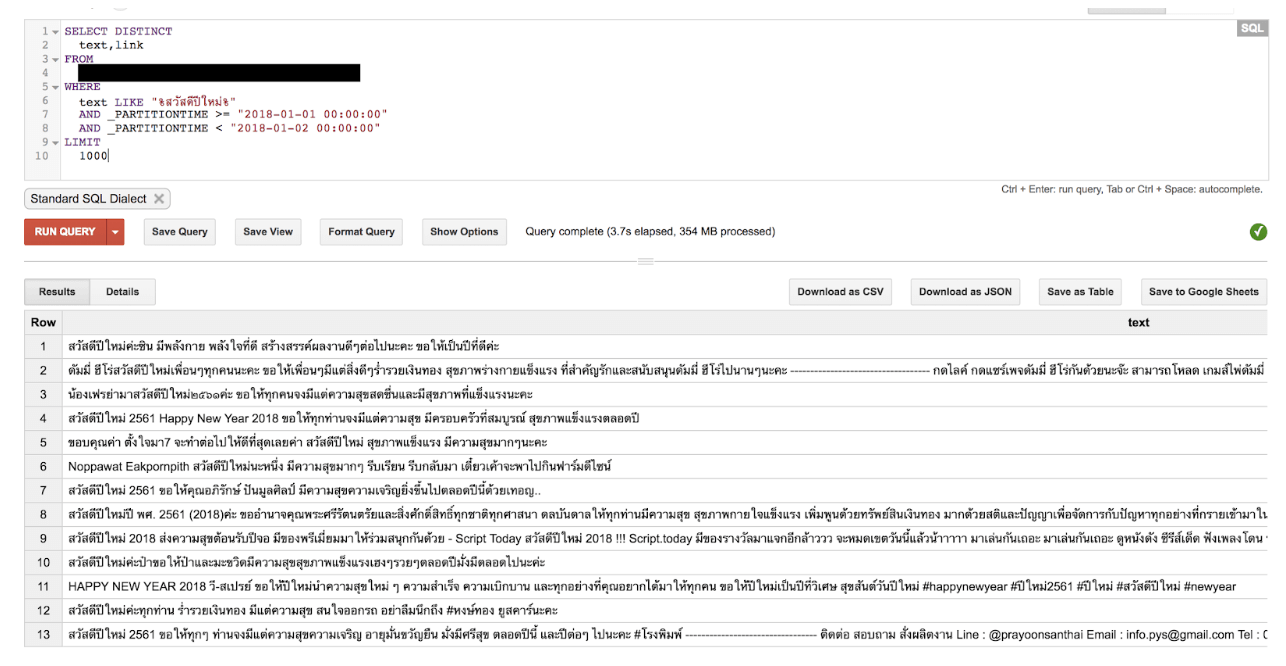
นี่คือตัวอย่างการหาข้อมูลที่มีคำว่า สวัสดีปีใหม่ในช่วงวันที่ 1 ถึงวันที่ 2 ของเดือนมกราคมนี้ จะเห็นว่าใช้เวลาราว ๆ 4 วินาทีเท่านั้น ในการค้นหาข้อมูลที่เราต้องการจากข้อมูลประมาณ 1,500,000 แถวของข้อมูลซึ่งรวดเร็วมาก
Partitioned Table คืออะไร
ใน BigQuery จะมีการคิดเงินแบบที่คิดจากจำนวนข้อมูลที่ process ซึ่งคิดง่าย ๆ คือ field นั้น ของทั้ง table ซึ่งใช้เวลานานและเปลือง จึงต้องมี feature อย่าง Partitioned Table มาช่วย โดย Partitioned Table คือการแบ่ง table เป็น segment ย่อยๆ ตามวัน ซึ่งเมื่อเรา query ก็แค่บอกของเขตของ partition ที่ต้องการก็จะทำให้ ข้อมูลที่เราต้องแตะในการ query น้อยลง ซึ่งก็แปลว่าเงินที่เราต้องเสียก็จะน้อยลงไปด้วยนั่นเอง
ข้อจำกัดของ BigQuery และปัญหาที่เราเจอ
Data Loading limitation
สำหรับข้อจำกัดในการใช้งานที่เราเจอนั้น เกิดขึ้นตอน migrate ข้อมูลเข้าไปใน BigQuery เนื่องจากตอนแรกเรานำข้อมูลจำนวนมากในฐานข้อมูลของเราเองใส่เข้าไป โดยการแบ่งเป็นไฟล์ย่อย ๆ ที่ไม่ใหญ่มาก และทีนี้เราก็พบว่า

มันมีข้อจำกัดของการโหลดอยู่ ว่าในแต่ละ table สามารถโหลด job ได้เพียง 1000 jobs และยังมีอีกข้อนึงที่สำคัญ นั่นคือ…

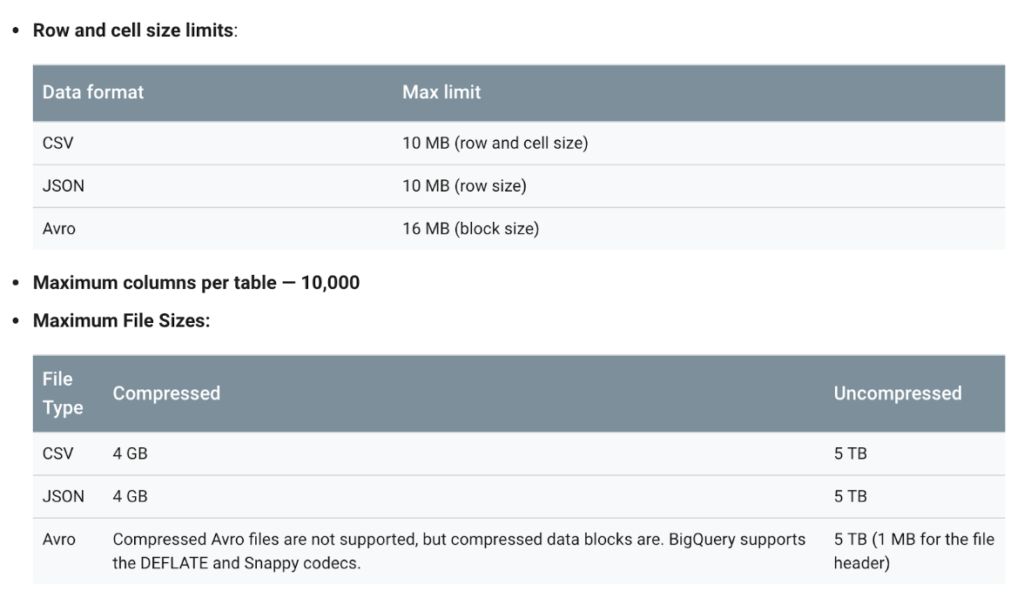
Limit ตัวนี้มันเพิ่มไม่ได้ ทีนี้เราเลยต้องเขียนไฟล์ให้ขนาดใหญ่กำลังดี โดยมีข้อจำกัดของไฟล์ที่จะโหลดอีกว่าในแต่ละ format limit ไม่เท่ากัน
Partitioned Table limitation

สำหรับข้อแรกนั้น ตัว Partitioned Table ยังไม่สนับสนุนการจัดการ data ต่าง ๆ (Update, Insert, Delete) จึงทำให้การแก้ไขข้อมูลยังทำได้ยากพอสมควร และข้อสองนี้คือ Limitation ของมัน

ใน table หนึ่งจะมี partition อยู่ได้เพียง 2,500 partitions ซึ่งนั่นหมายความว่ามันจะสามารถเก็บข้อมูลต่อวันได้เพียง 6 ปีกว่าๆ เท่านั้น เราจึงต้องหมั่นตรวจสอบและเคลียร์ partition หากว่ามีข้อมูลที่เก่าเกินไปเป็นจำนวนมาก
Duplicated data
ปัญหาที่เราเจออีกข้อหนึ่งนั่นก็คือ การเจอข้อมูลซ้ำ โดยหลักๆ ก็จะเกิดขึ้นเพราะปัญหาจากการเอาข้อมูลเข้าเพราะว่า BigQuery ไม่มี primary key ซึ่งเราก็พบปัญหานี้อยู่บ้าง โดยวิธีการแก้ไขเฉพาะหน้าในกรณีที่เราใช้ SQL แบบ legacy ก็สามารถใช้คำสั่ง GROUP BY เพื่อแก้ปัญหาการเรียกข้อมูลซ้ำซ้อนได้ หรือถ้าหากใช้ Standard SQL ก็สามารถใช้ SELECT DISTINCT เพื่อกรองข้อมูลซ้ำได้เช่นกัน
Data Streaming limitation
การเอาข้อมูลเข้า BigQuery ด้วยวิธีนี้มีข้อจำกัดคือ เราสามารถเอาข้อมูลเข้า date partition ได้ตามช่วงเวลาที่กำหนดเท่านั้น
- ย้อนหลังได้ 30 วัน
- อนาคตอีก 5 วัน
ยกตัวอย่างเช่น วันนี้วันที่ 31 มกราคม เราสามารถใส่ข้อมูลเข้า date partiotion ระหว่าง 1 มกราคม ถึง 5 กุมภาพันธ์ โดยประมาณเท่านั้น ข้อมูลที่อยู่นอกเหนือช่วงเวลานี้ต้องใช้วิธี load data เป็น job ที่ได้กล่าวมาก่อนหน้านี้
ความคุ้มค่า
BigQuery คิดค่าใช้จ่ายตามการใช้งานจริง โดยคิดจากปัจจัยต่าง ๆ ดังนี้
- Storage ตามการใช้งานจริง
- Streaming insert ตอนเอา data เข้า
- จำนวนของ Query เทียบกับปริมษณข้อมูลที่เข้าไปประมวลผล
รายละเอียดดูได้จากที่นี่ https://cloud.google.com/bigquery/pricing
สำหรับที่ ThothZocial ที่เน้นความรวดเร็วและความพึงพอใจของลูกค้าเป็นหลักถือว่าคุ้มมาก เพราะเป็นเครื่องมือที่ตอบโจทย์กับการประมวลผลข้อมูลขนาดใหญ่ได้อย่างรวดเร็ว อีกทั้งยังสะดวกกับทีมพัฒนาของเราที่ไม่ต้องตั้ง servers และ setup software อย่างพวก Elasticsearch ขึ้นมาเองเพื่อการทำงานในลักษณะนี้ ลด effort ในการซ่อมบำรุงดูแลรักษา ซึ่งช่วยให้เราประหยัด cost ลงไปได้ 20-30%
อีกทั้งช่วยทำให้ทีมสามารถไป focus กับการทำงานด้านเว็บและพัฒนา features ใหม่ ๆ แทน
สรุปแล้วเราคิดว่า BigQuery เองเป็นอีกทางเลือกที่ดีในการใช้งานสำหรับผู้ที่ต้องการค้นหาข้อมูลที่มีเวลามาเกี่ยวข้องได้อย่างรวดเร็ว
สำหรับผู้ที่สนใจ สามารถมาลองใช้กันได้ ตอนนี้ Google แจก Credit 300 ดอลลาร์ ให้มาลองเล่นกันฟรีๆ
บทความโดย: ทีมพัฒนา thothzocial.com
รูปประกอบบทความ: https://www.pexels.com/photo/abstract-art-blur-bright-373543/

